First, I should critique my own previous post. For example, I currently feel more confident about preventing rare diseases than guiding drug treatments. However, I think there was a sense in the limits to prediction that I was trying to convey before (in terms of "designer babies" where a large number of traits could be predicted and selected), and I still don't support that (or necessarily believe that can / should be accomplished). I think this is also emphasized in the HFEA guidelines (described on page 55, in my edition) as well as some more updated scientist options (such as not using Polygenic Risk Scores for embryo screening).
I still really like that Francis Collins provided a balanced view of genomics (with both potential and limits), and I was glad to see that I could also notice that ~10 years ago.
My earlier post also reminded me of the statistic that "[adverse] drug reactions are the fifth leading cause of death in the United States" (page 233, in my edition), although I admittedly also forgot that in between the time that I first marked that page with a book dart and when I started writing the draft for this post.
Going back to the genomics and drug treatments, Francis Collins also mentions "the biggest reason for potentially deadly drug reactions is simple human error [but this isn't the only reason]" (page 233, in my edition). So, even though I implied that I had less confidence in pharmacogenomics (or at least I think we have to be more careful about the assessments than I used to), I really do think biomedical informatics can help patient care. In other words, making sure relatively simple actions are consistently understood and carried out appropriately is not trivial (which I also touch on when describing my cystic fibrosis carrier status, even though I believe that is more complicated than some people may expect), and that is something important that we can improve (without even using exceptionally complicated models / techniques). Nevertheless, to be clear, this area was fairly represented in the book, with an entire section of the 9th chapter called "Obstacles to the Pharmogenomics Revolution" (page 247-249, in my edition).
Now, in terms of my updated thoughts:
1) In the introduction, "Dr. James" (who was really Francis Collins) describes interacting with somebody with a BRCA1 mutation in their mother's DNA, saying "[the patient] faced a 50 percent risk of having inherited that misspelling, in which case her lifetime risk of breast cancer would be approximately 80 percent, and that of ovarian cancer about 50 percent" (page XII, in my edition). However, I think I have more recently gained better appreciation for the value in the range of risk estimates (at the gene or variant level). For example, there is a Stanford BRCA Decision Tool that provides the variance of risk with a few options (although I'm not sure about the the intervals of screening, I don't know what is the relative effectiveness of hormonal therapies, and these estimates are at the gene level when I would expect some specific variants are higher risk than others). Likewise, there was a recommendation for BRCA screening with a "B" grade in individuals with family histories, but a recommendation against BRCA screening with a "D" grade (which I think is shown most clearly on the US Preventive Services website). In other words, I believe the significance of the result (and the preventive option chosen) varies depending upon whether the individual has a family history of early-onset breast cancer (ideally, I believe, with a variant that specifically validates between cases and controls in their own family).
In the interests of space, I have saved a collection of informal notes in another blog post. This includes some things like strategies to define risk from family history from the CDC.
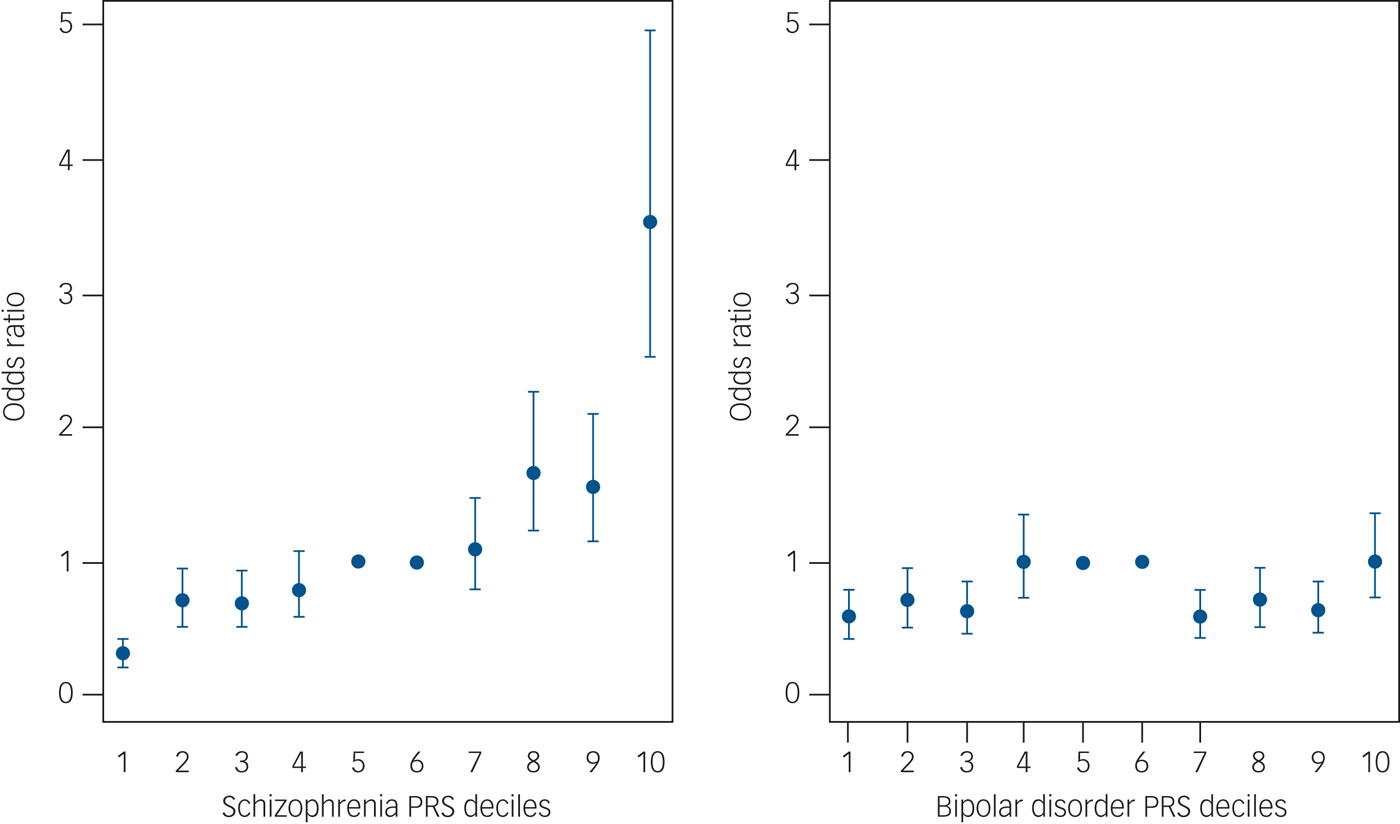
2) On page 194 (in my edition), Francis Collins describes "a company called Psynomics is marketing a DNA test for susceptibility to bipolar disorder, arguing that this information could be useful in establishing the diagnosis in an uncertain case. The test being offered, however, is based upon a variation in a gene called GRK3, and this has not been validated in a large-scale study. This result could turn out to be utterly useless. Even worse, this kind of unvalidated test, utilized by individuals or their physicians to make a serious diagnosis in an uncertain situation, might do more harm than good." As with pretty much all of the posts, I will probably update my review of "Blueprint", but I agree with concerns about the over-estimation in the accuracy of tests that can possibly negatively impact the rest of someone's life (as well as my opinion that the reaction to genetic results may be particularly important for mental health).
Similarly, on page 204, a company offering testing of V1aR variants for $99 to test for increased susceptibility to infidelity is also presented with an appropriately critical view that "the actual influence on the behavior of an individual male is quite modest, and should certainly not be used in mate selection or as an excuse for cheating on one's partner.
3) Perhaps it is a bit of a tangent; however, in terms of the rare diseases, the first episode of Diagnosis on Netflix involves a patient story that was resolved with Whole Genome Sequencing (WGS) to determine the cause of her ailments for the past 10 years were due to CPT2 (meaning her symptoms could improve by increasing sugar and decreasing fatty acids in her diet). I was surprised that she went to Italy for the diagnosis (where she was treated for free after the arrived, but I would have expected treatment costs to usually be above a few thousand dollars to justify the trip; I could get Veritas WGS data for $1000, but I did need to re-analyze it).
I was also surprised that her US doctors were trying to sue her for hundreds of dollars of medical bills (when she was already in debt, and the treatments weren't helping her in the long-run since they didn't reveal the underlying problem). However, that unfortunately seems like it may not be an isolated incident: for example, I recently heard about this happening to a large number of individuals in the UVA health system.
However, getting back to this book, on page 92 (in my edition), Francis Collins warns that some nutrigenomics companies are running "consumer scams," while there are legitimate rare diseases whose symptoms can be improved with diet (such as PKU). I was also skeptical about some of my nutrigenomics results, but it sounds like the Netflix show also provides a genuine example where genetics can inform diet (and vastly improve your quality of life).
Also, similar to my 1st post, here are some assorted minor points:
a) Francis Collins (as Dr. James) indicated some someone from Navigenics implied that "most of the remaining genetic risk factors for common disease will have been discovered in the next two or three years; as a scientist working in this field, that seems unlikely to me" (page XXII, in my edition, emphasis added). I also don't think Navigenics exists anymore - at least the Wikipedia company link does not go to a genetics company website (even though they also mention it was acquired by Thermo Fisher in 2014).
b) As noted in the first post, Francis Collins has blue eyes when 23andMe predicted them to be brown (page XXVIII, in my edition).
c) I am a Bioinformatics Specialist (doing genomics research). However, I don't think that term was in widespread use when the book was written. For example, I believe his term "DNA cryptography" (page 13, in my edition) is meant to be synonymous with "Bioinformatics."
d) Reading this book also influenced another blog post, in terms of the discussion of the ACLU Supreme Court case invalidating Myriad's patents on the BRCA1/2 genes and contrasting his own actions for the CFTR gene for cystic fibrosis.
e) On page 187 (in my edition), Francis Collins describes "[one] remarkable gene in the brain is estimated to be able to make 38,000 different proteins." However, I kind of wish there was a reference to the citation in the primary literature. For example, I thought most cells tended to have one predominant version of a gene transcript, and I am worried about false positives (or at least rare alternative splicing events) when describing very large numbers of isoforms for genes.
f) On page 317 (in my edition), 23andMe is listed as testing for the Δ508 cystic fibrosis variant. While I got my first 23andMe test in 2011 (a little after this book was published), I am a carrier for a different cystic fibrosis variant. So, 23andMe currently covers more than just that one cystic fibrosis variant.
Finally, I specify "in this edition" whenever I reference something from the book. However, I think the relatively newly purchased paperback was still the 1st edition. So, I'm not sure how necessary this is. However, in terms of trying to minimize errors in peer-reviewed publications (and making sure people acknowledge and correct errors), I think the concept that books have editions may be kind of important.
Update (10/19/2019): After I finished re-reading the book (again - to prepare for leading the book club discussion), I thought I should write a little more to make sure that I am to down-playing the pharmacogenomics part too much. While I do think the introduction is a fair match to my interests / opinions, I do want to make clear that I am sure there are important genomic applications with decent predictive power for guiding drug dosage, drug effectiveness, and/or serious adverse side effects.
So, similar to the separate blog posts containing notes on BRCA1/2 pathogenic risk, high-to-moderate inherited cancer risk frequencies for pathogenic variants, and APOE variant frequencies and Alzheimer's Disease risk, I will try to add a few links about the influence of VKORC1 on Warfarin / Coumadin dosage. However, I have spent considerably less time looking into that, so this will just be bullet points below (instead of a separate blog post):
- Rieder et al 2005 - paper cited in the figure caption in the book (I think "Haplotype" concept is made a little more clear in the original figure, as well as explaining the use of "A" and "B" in the book)
- There is a more recent 2009 paper, but the genotypes are described in a different way (and what I wanted to do was try to judge if there should have been larger error bars in the earlier paper).
- For example, Figure 2 in the 2005 paper matches the sort of error bars that I was expecting with VKORC1 gene expression (which is noticeably larger)
- Limdi et al. 2010 - paper showing variant predictive power across racial groups; mentions both SNP and haplotype, but I mostly notice that the variant is at 91.03% in the Asian population, 10.05% in the African population, and 37.81% in the Caucasian population(so, variability is not equal from individuals with different ancestry)
- 23andMe blog posts with "Warfarin" tag - there is a blog post mentioning providing a 23andMe report for the variants listed on the label, but perhaps that doesn't have approval to be added back?
- FDA Coumadin labels - describes GG, AG, AA genotypes for 1639G>A variant (which actually would be a SNP, even though SNPs sometimes do represent larger haplotypes)
- ClinVar link above actually only has 2 stars, but "Warfarin Response" in MedGene has more information, included dbSNP ID (rs9923231) and that variant also has clinical annotations in PharmGKB
- The variant in intergenic, but you can see your genotype (I am CC, which should be GG in format above), even without a formal report --> from PharmGKB, I can tell I have the variant associated with requiring a higher dose
On the other hand, I really do have some interest in understanding (and critically assessing) the use of genomics for depression treatment. I have tried to collect some notes on that within my review of "blueprint", as well as expressing concerns I have about what people might percieve about the predictive power of genomic data and anxiety / depression (based upon my own personal experience as well as some general genomics research experience).
Change Log:
9/7/2019 - public post date
9/8/2019 - revise post from sister's feedback; minor changes
9/9/2019 - add UVA example + NCCN guidelines + additional Twitter / blog link
9/10/2019 - minor changes
9/13/2019 - add links from the CDC
9/14/2019 - move longer set of BRCA1/2 notes to separate post
10/19/2019 - add update with pharmacogenomic notes