can also be important for interpretation. In an earlier version of this blog post, I had a plot of ranks from
, but I noticed more recently that the linked image was not appearing in the post. So, I kept searching, and I found some data from
You might also notice that the correlation coefficients are both lower than mentioned in Blueprint: as much as possible, I hope independent validation in multiple large cohorts is helpful, and transparency in data and sample section/filtering is also important. However, at the current time, I am not sure what explains the difference in correlation coefficient, even if both datasets come to the same conclusion that the genetic impact is higher for monozygotic twins than dizygotic twins.
In terms of an introduction, I think
Chapter 12 (The DNA fortune teller) is quite good in terms of explaining how PRS are calculated and presented (although I kind of whish it was called something different, like "
Introduction to Polygenic Risk Scores," since the main thing that was clear to me was the limitations and that seems strange for something called a "
fortune teller"). For example, that chapter says "[
the] most predictive polygenic risk score so far is height, which explains 17 per cent of the variance in adult height" (
emphasis added, page 139 in paperback edition) as well as showing a scatterplot for actual height versus PRS for height (
Figure 5, page 142, paperback edition), and Robert Plomin specifically has an actual height at the 99th percentile but a PRS for height in the 90th percentile (as a sort of "best case scenario" for a PRS).
Similarly, the Plomin's PRS for BMI was at the 94th percentile, while his actual BMI was at the 70th percentile (page 146, paperback edition). He explains this in terms of being at the 99th percentile for height and possibly having to take extra effort to keep off weight (which I think sounds like a plausible combination of factors, in addition to general limits to predictive power). If most people consider this as a motivating factor (similar to the author), perhaps that is good.
I also really like that Plomin gives examples of PRS percentiles for himself (Figure 11 on page 160, paperback edition): 22% for bipolar disorder, 35% for major depressive disorder, 39% for Alzheimer's disease, 85% for schizophrenia, and 94% for educational attainment. That said, while I think some of his "self-understanding" discussions about his schizophrenia PRS may be acceptable in a research setting (page 151 and 177 in the paperback edition), it sounds like
85% is not a high enough score to be relevant in a clinical setting (if something like the PRS could increase the chance of somebody being institutionalized with less direct evidence). This kind of makes sense for a disease with less than 1% prevalence, although I think that does bring into question the value of using common variants (instead of rare variants) in the PRS calculation.
Another useful plot is
density plots for extreme values (with the range and overlap of PRS values for each of those populations. Again, I am trying to show you something in the book without copying it, but
I can make some representative examples in R:
For example, I would say the simulated example on the left looks good, but the utility of the example on the right could be questionable (although I think this is encountered more often, especially if you took a randomly selected trait and your own generated PRS).
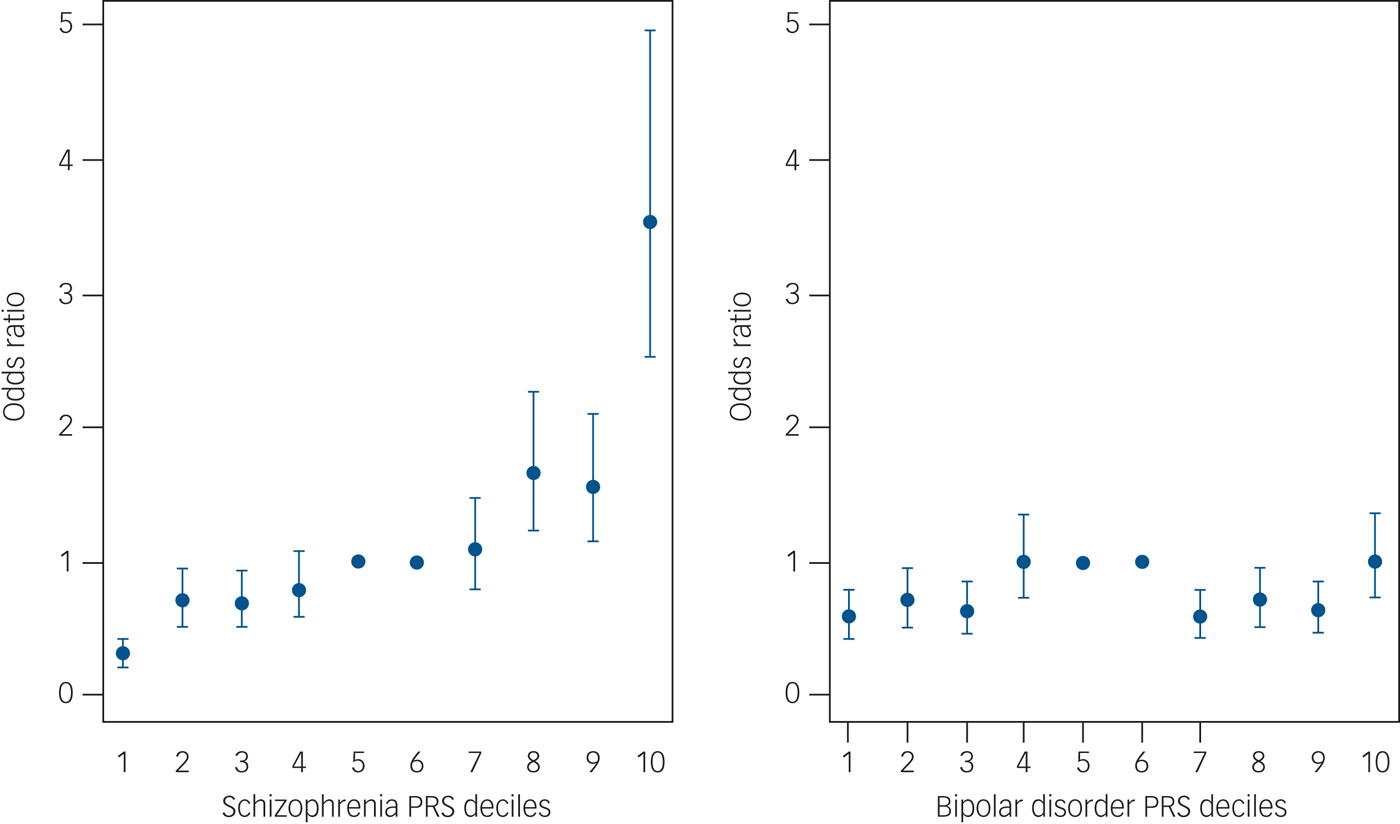
On the other hand, what I thought could be misleading was the
decile plot shown in
Figure 6 on page 144 in the paperback edition. Yet again, I'll use an example on-line (from
Figure 3 of
Calafato et al. 2018, instead of in the book). However, one of my top Google searches happened to be for psychiatric traits (rather than height as a positive example):
To be fair, this does make the schizophrenia PRS look like it may have some value with a percentile >90% (matching the expectation not too much should be read into for the 85% PRS for the author), and it looks like the bipolar PRS is probably of limited utility.
Nevertheless, you might have something that is not very predictive (with a lot of variability in the scatter plot) in a decile plot that looks like the 1st 9 deciles for schizophrenia (in that paper).
While I think the example with height was meant to give some sense of an inflection point above the 80th percentile, I think this does not do a good job of capturing the variability that you would see in a scatter plot (
so, I think showing a scatter plots and density plots should be required for any PRS). In particular, I believe the crucial point is made by Plomin on pages 143-144 (
emphasis added): "
The line running through each data point [in the decile plot] is called the standard error...Note that the standard error refers to the average of each group, not the error of estimating an individual's score...It does not mean that the actual height of 95 per cent of individuals in the top decile of polygenic scores will be in this range."
Second, I admittedly started the book with a bit of a negative impression - the prologue mentions predicting depression (and schizophrenia / school achievement) "
from the moment of your birth, it is completely reliable and unbiased - and it costs only £100" (page vii, paperback edition). As somebody who has had to manage anxiety and depression, I know that symptoms are context-dependent and change over time. So, even without taking limitations to the genomics predictions into consideration, I would say that something like "probability of having at least 1 depressive episode" likely has a genetic component, but whether or not you have depression / anxiety at any particular interval (and whether or not that requires medication) will require additional factors. In other words, I think there are a lot of exceptions to the assumption "
[psychologists] study hundreds of traits, which is their collective label for differences between us that are consistent across time and across situations" (page 3, paperback edition).
I also don't believe I completely agree with the claim "
[for] the first time, genetics offers a causal basis for predicting disorders rather than waiting until symptoms appear and trying to use these symptoms, rather than causes, to diagnose disorders" (page 66 in the paperback edition). For example, I believe I even had a psychiatrist who explicitly said that getting caught up on the names for the diagnosis can sometimes cause problems beyond trying to treat symptoms. However, I do agree that "
[whether] you become anxious or you become depressed is caused by environmental factors" and I believe there is some useful insight in terms of clustering "
internalizing problems" and "
externalizing problems" (both on page 67 in the paperback edition).
Additionally, I think there is an important point being made about continuous traits and PRS values on page 164 in the paperback edition: "
A second way in which polygenic risk scores will transform clinical psychiatry is by moving away from diagnoses and towards dimensions. One of the big findings in this book is that the abnormal is normal, meaning that, from a genetic perspective, there are no qualitative disorders, only quantitative dimensions". So, practically speaking, on the trait side, there are certain thresholds for needing to take action (such as not being able to function at work, at least without treatment / adaptations). Likewise, I believe you still need concrete examples of less severe behavior to watch out for, in order to possibly identify problems early and prevent progression.
I certainly hope that there can be ways to better identify problems at an early stage in order to have the sort of prevention described on page x (of the paperback edition), but I think it is also important to be realistic about predictive power. In other words, if the true predictive power is lower than you expect, then providing a diagnosis based upon DNA sequence alone (at least using one strategy of interpretation) might contribute to unnecessary stigma for a patient. Given the prevalence of depression, I think there are a number of things that probably should be done to improve perception of mental illness (so, a false positive would be less of a big deal). However, I would be more concerned if limits in predictive power were not properly understood in situations where a false positive could negatively impact the rest of a person's life (if we
assume a person will have a severe mental health problem, without any evidence from their actual behavior). So, it is the part about "
This means that we can foretell our futures from birth. For example, in the case of mental illness, we no longer need to wait until people show brain or behavioral signs of the illness and then rely on asking them about their symptoms" (
emphasis added, page x of my paperback edition) that I think is either not being commentated precisely (especially in the present tense) or causes me concern.
To be fair, I have general experience with genomics research (and personal experience with mental health problems), but I didn't have any previous psychiatry research experience reading this book.
So, what may very well be true is that the genetic predictors are better than other risk factors. For example, Plomin says "
[there] are very few large effect sizes in psychology. On example is that general intelligence accounts for about 25% of variance in educational achievement." (page 31, paperback edition). However, I think it is also important to keep in mind how the predictive power for these traits / illnesses compares to other associations, and there is still a need to fairly judge each situation independently.
In other words, before reading this book, I thought I mostly remembered schizophrenia having the
least significant association. For example, in
Selzam et al. 2019 (with Robert Plomin as the last author),
the Polygenic Risk Scores in Figure 1 had significantly higher beta coefficients for height and BMI (or the other cognitive traits) than schizophrenia (SCZ), which was opaque in the lower-right because it's own p-value was greater than 0.01 (and the difference is indicated as
not being significant)
. Likewise,
this review concluded "
[these] limitations mean that [Polygenic Risk Scores] are not yet clinically useful in psychiatry." The book itself also describes
limited success for psychological disorders in a 2007 study, although studies with even greater sample sizes were emphasized after that (such as from the
Psychiatric Genomics Consortium).
However, to be fair, the
Figure 1 in the
PRS paper linked above does show better success in predicting educational attainment (General Certificate of Secondary Education, GCSE, in that paper). While I don't discuss it much in this post, this is a topic of discussion in multiple chapters of the book. As yet another way to compare PRS, the Epilogue of the book (on page 187 of the paperback edition) summarizes: "
polygenic scores...can predict 17 per cent of variance in height, 6 percent of variance in weight, 11 per cent of the variance in school achievement, 7 per cent of the variance in intelligence, and 7 per cent of the variance in liability to schizophrenia." However, I was less impressed with
Figure 10 density plots on page 158 of the paperback version of the book (showing density distributions for the top / bottom 10% of educational attainment PRS, as a function of GCSE score percentile), so perhaps the lower values than Height or BMI for the beta coefficients in the paper should also be emphasized (and, while I think the paper seems to be a better match to my expectations,
I don't believe this is entirely consistent with the relative percent variance explained in the Epilogue of the book).
Outside of the book, I did stumble across a gene that was specifically named because of it's association with schizophrenia (
DISC1, although that might have been from the NCBI entry for mouse name for
Disc1). However, it is probably also helpful to have numbers like "
if one sibling is diagnosed as schizophrenic, their siblings have a 9 per cent risk of being schizophrenic, much greater than the rate of 1 per cent across the general population" (
emphasis added, page 71, paperback edition). In that situation, there is considerably increased risk, but predictive power is still low. Likewise, I have concerns that the reader may over-estimate the predictive power from sentences like "
[for] schizophrenia, DNA differences packaged as polygenic risk scores are now the best predictor we have for who will become schizophrenic"(page 126 in the paperback edition), even though that may in fact be true (and the predictive power for other traits / risk factors is just worse).
There was also at least
one paper that indicated "twin studies [can overestimate] heritability," and my comment on that paper references a
pre-print where it looks like varying definitions of heritabilty can be used (between the twin 2*|cor
MZ - cor
DZ|) I also noticed that the
MaTCH entry for cystic fibrosis (under "ICF/ICD10 Subchapter") wasn't especially high; I'm not sure if that is an issue with sample size, but that makes me think this measure may not be absolutely perfect in terms of representing how well we understand the biology of a given disease (or the severity of the rare disease). I also thought it was strange that the dizygotic twin correlations were higher than the monozygotic twin correlations for cystic fibrosis. Perhaps I should look more into the associated
Polderman et al. 2015 paper.
I also noticed this
other blog post about the genomics in psychiatry (HT
@elo81). The context here is a little different. However, the article where I first heard about
Myriad's GeneSight had a subtitle that implied some confusion in the ability of this pharmacogenetic test to be used for diagnosis (which was not what the content of the article showed: you may be able to use genetics to guide testing different medications, but I didn't see any evidence that this particular test could diagnosis whether you actually have depression). Additional, this article says "
United HealthCare in August announced that it will cover panels of genetic test for guiding the use of drugs for major depression and other depressive disorders, although the American Psychiatric Association’s research council last year concluded that the evidence for testing in those indications is not conclusive", which I believe is specifically
in reference to GeneSight? Either way, the end of
this article has two citations (
Zeier et al. 2018 and
Zubenko et al. 2018) that discuss the field (the later of which describes clinical trials for GeneSight).
In general, you can also find some information on
ClinicalTrials.gov (for GeneSight). While some results are more clear than others, I thought this was interesting. For example, I think one was
"Completed" but actually canceled (under "Results Submitted")? One is
recruiting in Canada (this is for the US National Library of Medicine). Some can be complete yet have
"No Results Posted" (as opposed to not having results because the study still active). In fact, there was only one with results (
NCT01610063, out of the 10 from my search), and it has a link in the original table of search results (to make it stand out more).
There were twice as many lost to follow-up for the Guided (using GeneSight) versus Unguided treatment, but I don't know how often that happens. The difference for "primary outcome" (and multiple secondary outcomes) was
greater for
red category results than
green/
yellow combined category (
which matches my expectation that what would give me the most confidence was for me to have a red result and test taking the medication -
even though I don't recommend that for most people, particularly if you have no good reason to take such a risk).
I certainly don't want to downplay being able to identify adverse side effects better in 15-20% of patients (if I understand that correctly, that
does matter, particularly if you consistently see that between independent cohorts), but I also don't want people to think that the method was precise enough to predict exactly what they should take on the first try.
Third, I am sure I would be guilty of this if I tried to write an entire book (and this is part of why I have "change logs" on my blog posts), but there were some situations where I think there was some room for improvement in the wording. For example, I think there are some valid points within sections like "
Parents Matter, But They Don't Make A Difference" (page 82 in the paperback edition) or "
Schools Matter, But They Don't Make A Difference" (page 86 in the paperback edition), but there was understandably some complaints described in the afterword (page 191 in the paperback edition).
For example, on the positive side, the explanation of
what is and
what can be (at a population measure, as being reported in these studies) that is described several times in the book (including, but not limited to, page 192 in the paperback addition) is useful advice that I have used at least one time when making a point in causal conversation. However, using statistics as an incentive for change is different than than presenting fate as highly deterministic from genetics (and therefore predictive regardless of future action), and I think this is a caveat that may require less emphasis on the predictive power (and therefore hopefully avoid the need for this additional explanation).
In terms of sections like "
Life Experiences Matter, But They Don't Make A Difference" (page 89 in the paperback edition), I think Plomin is right to discourage people from being overly worried about small mistakes. However, figuring out what life experiences are traumatic enough to need extra effort to avoid is important. It is also my opinion that convergence of traits like personality and mental health over a long enough period of time can perhaps be though of like needing to go through
developmental stages (even as an adult), where certain concepts are easier to understand after you have gone through certain first-hand experiences. In other words,
I believe having some sort of anchor for clear understanding can be important for preventing certain problems; while I agree with tacking these issues as early as possible, I would therefore disagree that certain traits / diseases can be prevented from birth (if experience / communicating / logic are required to understand the underlying problem and modify behavior).
I also think it is
extremely important that Plomin acknowledges "
Severe genetic problems such as single-gene or chromosomal problems or severe environmental problems such as neglect or abuse can have devastating effects on children's cognitive and emotional development. But these devastating genetic and environmental events are, fortunately, rare and do not account for much variance in the population" (page 85 in the paperback edition). However, I think this may also get back to some limitation in the heritabiltiy measure for cystic fibrosis (a single-gene disorder that I believe is one of better examples some thing that can realistically be prevented with methods like
IVF+PGT).
Likewise, I thought an insightful example was provided in the Afterword on page 197 in the paperback edition: "
No prediction is perfect, especially in behavioral sciences. We often make big decisions on the basis of much weaker correlations. For example, the correlation between blood alcohol levels and automobile accidents is weak, but that doesn't, and shouldn't deter us from making strict laws about drunk-driving." I do wonder if perhaps choosing a title other than "
blueprint: how DNA makes us who we are" would have helped with the "
No prediction is perfect" part, but that is also discussed in the Afterword (on page 190-191 in the paperback edition).
Fourth, on page 180 in the paperback edition, Plomin mentions "
dating websites might extend their data to include polygenic scores...Unlike the hype of dating websites, polygenic-score information could be verifiable through password-protected links to a direct-to-consumer company". While the limits to predictive power in "percent match" on dating websites might be a good analogy to the limits to "
hypothesis generation" for some genomics applications, I certainly wouldn't encourage something like this. Plus, I'm not quite as certain about the genomics verification being foolproof (which also means that I would at least somewhat disagree with the sentence on page 181 that "
You can't fake or train your DNA"). For example, I had a
strange experience when I uploaded my 23andMe data into FamilyTreeDNA, and Francis Collins was able to submit his DNA sample under another name to mutiple companies (as described in the prologue to T
he Language of Life, which is a book that I admittedly prefer, and I have
a blog post with an updated summary of thoughts as well as
a set of discussion questions for a book club).
Similarly, I have some concerns about the suggestion of using polygenic risk scores for job interviews (mentioned on page 181 of the paperback version), even though I certainly acknowledge limitations in fairly accessing somebody during a brief screening / interview process.
To be clear, I don't expect any system to be completely foolproof (kind of like it is possible to pay somebody to take your SATs, but that is rare and we have only heard about wealthy people doing that). However, I still strongly disagree with using PRS for dating apps or job applications, which I believe is in line with the view that
PRS should usually not be used for embryo selection.
Finally, on a closing note, the Afterword has a section called "Public Reaction" (pages 199 in the paperback edition). Plomin describes a highly positive response after describing critiques from scientists and the media: "
Far from the nightmare predicted before publication, the public reaction has been positive beyond my wildest dreams." However, my concern that individuals with less background in an area may initially have a more positive reaction, but those individuals may have a more negative reaction in the long run (if there were limitations that were not made clear to them, especially if they repeated incorrect or imprecise information to others). While I realize this can make success hard to define, I think this may be important for many genomics researchers and companies.
Change Log:
9/7/2019 - public post date
9/8/2019 - fix typos; minor changes
9/16/2019 - add early link to book; minor changes
9/20/2019 - add pre-print citation
10/1/2019 - add other review link + minor subsequent changes
10/2/2019 - add links related to GeneSight
10/20/2019 - add ClinicalTrials.org links
11/14/2019 - add link to swirl lesson with Galton's height data.
7/6/2020 - change tense for "polygenic risk score" label
7/9/2022 - provide alternative BMI scatterplot, and modify content accordingly; minor changes
Also, I moved the following paragraph out of the main text, given that I found it somewhat confusing on re-reading (even if the view of the variation might in fact be of some interest):
Also, for reasons of brevity, I thought it might help to move out the following content (and re-number the later sections):