NOTE: If this post is too wordy and/or contains too many details for a broader audience, then I would recommend viewing this YouTube video (from somebody else, with a different cat). However, those comparisons do not consider the UC-Davis VGL (Veterinary Genetics Laboratory) report or the Whole Genome Sequencing results (from Basepaws). So, if you might be interested in information for those other options, then I hope this blog post may be useful! Nevertheless, I think some main messages are similar with an independent assessment.
However, Stormy is not my cat. So, I decided to test my cat (Bastu) for a few different options out there for the general public. While more recently expanded, this started from notes that you can see on this GitHub page (including subfolders for most of the raw basepaws analysis). I am also continuing to upload updated basepaws reports there.

UC-Davis VGL (Cat Ancestry, $120)
- You can see Bastu's VGL report here
- I would recommend visiting the VGL cat website to learn more about the genetic tests (often used across companies).
- I also like that trait information is provided for specific variants, most directly related to the phenotypes of interest.
- So, I think "Cat Ancestry" is a nice brief report, which also includes checking for some mutations associated with traits (sometimes for a trait defining a breed).
- Saliva sample collected with cytobrushes.
- In terms of ancestry, I think these tend to be the most robust results in terms of "Eastern" versus "Western" ancestry (some people on the basepaws discussion forum didn't initially like them because lack of detail, but I believe some of the more "interesting" results may be less robust and/or are commonly misunderstood).
- At least when I ordered the kit, I think this option has the longest turn-around time (I noted that the last kit had a turn-around time of a little more than 3 months).

basepaws lcWGS + Amplicon-Seq (regular price $149)
- The more recent reports are interactive (where I "printed" a PDF to download), and you might want to download the files (selecting the green "Code" button and then "Download ZIP") from GitHub link to view the full names for all of those files.
- Nevertheless, you can see various versions of Bastu's reports here.
- For either sample type, I liked the basepaws Facebook discussion group (Basepaws Cat Club), to become part of a community with other cat lovers.
- The text related to reports to the reports can often make me feel uneasy, and I have been working on resisting commenting about that as often (since I don't want to say nothing at any point, but I also don't want to harass the other customers).
- However, posts that focus on seeing other people's cats is something nice that is helpful in making my day a little better.
- I also like the vibe of the company, in terms of having a blog and fun merchandise
- For example, I purchased a Whiskers Face Mask for myself (but please note I had an extra $4 for shipping, and I didn't initially notice that it said "basepaws" in small font). I have some face masks, but I thought this looked extra fun!
- Sample previously collected with material like packing tape (for hair), but more recent sample collected with foam swab with preservation material (for saliva)
- The foam swab is supposed to be inserted into the cat's mouth for 5 seconds
- This may change in the future, but I also have some concerns about the representation of the company and timing/expansion of company offering. I would no longer have concerns if this was changed, but there are multiple examples of this:
- As one example, at least currently, I think they need to add the word "consumer" to their CatKit box (for example, the VGL results were clearly available earlier). However, if this is changed, then I no longer have this concern.
- On the plus side, I believe the need to do this has been acknowledged. However, I think it has still not been added the to the box for the kits.
- To be clear, I think pretty much everything in this post would benefit from continual evaluation/verification, and drawing similar conclusions from independent data/experiments is important.
- So, the point is not to emphasize whomever is "first" so much as not being able to say that you were first (and there being evidence against making this specific claim).
- As another example, under "About Basepaws," the Cat Behavior Summit website says "Basepaws is a leader in feline health, providing world's first at-home genetics and biome testing with digital results available in weeks." Again, basepaws did not offer the first at-home genetics testing for cats. Additionally, there are currently no biome testing results in the report (at the time that information was posted - I do currently have a metagenomics report for my regular coverage sequencing data).
- It is possible to do microbiome/metagenomic analysis with low coverage Whole Genome Sequencing (lcWGS) results, but I do not believe it is accurate to say this in the present tense.
- I have been notified as a plan for basepaws to add a dental health test. I did see a similar number (50-90%) reported on this page for cats, and an estimate of 77% on this page would also be overlapping (for the broad category).
- Again, for any level of severity, if you count 50-70% as being similar, then that overlaps what is reported here and perhaps pages 10-11 of this report.
- However, I think the claim about prevalence looks different than I see in this paper on dogs. Likewise, I can also see this paper where the prevalence is more similar to what I saw in cats (10-15% for periodontal disease, which was in fact reported as being the most common specific disease)
- Possibly somewhere in between, in this paper, there was a fraction of overall "dental" problems being reported in the abstract is ~30%.
- I don't see dental problems listed on this ASPCA page, (or, I believe, this Wikipedia page). So, I am not sure what to think about that.
- I will continue to gradually look into this more, but the "periodontal disease stage" for dogs (and stage I, for cats) in the 2016 VCA report earlier (with a higher percentage for "dental tartar") seems like what I was expecting (with values <10% for stage I cats, and varying fractions by age for dog that are also all <10%).
- Though this video, I have also learned about things like VOHC.
- That said, if the raw data was provided for all kits, then I would be OK with those having enough familiarity/background to use open-source software can test different ways of looking at the data (with an understanding that you may not be able to make any confident claims about the interpretation of those results, and the customer base for that is probably more limited).
- I also have some more specific scientific/technical concerns about the ancestry / breed results below. So, I would say that there are still noticeable issues with what is currently being provided, before expanding into something more noticeably different.
- That said, to be fair, and I have similar notes on human genomics companies (as well as discussions on the science-wide error rate with personal experiences and corrections / retractions on other papers). So, I hope that shared experiences about past mistakes can help each of us learn the best way that we can help make the world a better place.
- I myself am trying to figure how how to work on fewer projects in fewer depth that are ideally of good quality. So, I think it is possible that a limit on the total number of commitments might be relevant on any time frame.
- I think it is usually hard to be too nice, and I think compassion is important for managing your own stress as well as others. However, if these things were being done intentionally, then I think I should say that is somewhat different. Either way, I also think paths to redemption need to be available to everybody.
- I very much like that the likelihood of future changes in the report is often repeated basepaws, but there are some parts of the report that I have concerns about.
- For example, I think the idea of hybrid breeds (like the Savannah) is genuinely interesting, but I think giving percentiles for the wild cat index to large cats (like tigers and cheetahs) is frequently giving consumers the wrong impression in terms of the biological significance of a result (and that percentiles can be defined for a completely random value, like a null distribution).
- To further emphasize that the wildcat percentiles don't reflect absolute differences, you can see a phylogenetic tree from Wikipedia here. For example, you can see all domestic cats should be more closely related to a cougar or a cheetah than a tiger or a leopard. So, if your cat has tiger ranked first, then that doesn't mean that your cat is most closely related to tiger than the other 3 wildcats.
- To be fair, the report does say "[these] results should NOT be interpreted as evidence that your cat is part wildcat".
- I also have concerns with the specific breed index.
- For example, I think the Savannah also provides a good example of my concerns with the domestic cat breed index (where the majority of customers with Savannah as their top breed probably don't have cats that descend from Savannah cats), and you can see some notes about that here.
- I am also going to show you below how much this varies for technical replicates for my 1 cat.
- In general, I think the Facebook discussion group has done a good job of providing examples of false positives and false negatives for using the breed index to define breeds.
- However, to be fair, there is a warning that "[the] Basepaws Breed Index is not a breed test, and can not tell exactly what breed your cat is.".
- I also have a lengthier explanation on this specific point in a newer blog post, but I think a lot of the individual points are also mentioned in this post.
- Also, as I mention in the Facebook discussion group, you can see some things that worked well for my human lcWGS data and some things that were unacceptable for my human lcWGS data. I am also assuming that human variation is better understood than cat variation, which might relate to some of what I am about to show. However, even for people, my country-specific AncestryDNA predictions of ~20% have confidence intervals that go down to 0%.
- I think this is somewhat good in that it shows they understand the need to have the Amplicon-Seq for specific mutations (if using lcWGS).
- However, if it was me, I would only provide Eastern-Western ancestry estimates and the relative finder functions (without providing genome-wide distances to purebred cats of unknown total number from reference set).
I also ordered a second lcWGS + Amplicon-Seq kit from basepaws for Bastu. The mutation results and broad ancestry results were similar, but you can see differences in the exact values and top percentiles among technical replicates:





For the custom re-analysis, one thing that I think is kind of neat is the separation that you can see between Eastern and Western reference samples (even with a relatively small number of probes on the cat SNP chip):

Even if there can be some improvement for the specific species, there is already some noticeable overlap if you try to separate the Persians from the Western cats. However, what I thought might be possibly interesting is that Bastu was arguably slightly closer to the Maine Coon (and the UC-Davis VGL Cat Ancestry showed that she was an M3 carrier, which believe was found in a decent proportion of Maine Coons):

In terms of testing Bastu's mutations from UC-Davis, 2 out of the 3 showed reasonable validation:


I saw one read including the 3rd variant, although I am not sure why it was at so low frequency. At least currently, I don't feel the strong desire to see if I can get something closer to 50% frequency with more starting DNA, but I can leave this as something to ponder for the future (and note that the UC-Davis VGL and Optimal Selection samples were also saliva samples patiently collected from Bastu's cat mouth, although the mechanism was slightly different). Either way, her heterozygous status was validated on the 5th page of the Optimal Selection report (the 2nd page of the "Trait" section), so I believe this is her true genotype (and it's also possible the read ratio may improve with higher coverage).


The issue with the above image is that I would have expected more variation in ancestry between the two copies of chromosomes.


Change Log:
12/18/2019 - public post
12/21/2019 - minor updates
12/28/2019 - revise content for clarity
1/8/2020 - add a couple more screenshots; update Bastu's report to include Amplicon-Seq disease variants
1/9/2020 - mention longer turn-around time for UC-Davis VGL; remove holiday prices for basepaws
5/8/2020 - add technical replicate results

You can also see this report, which I submitted to FDA MedWatch. However, please note that I do not believe that this was the right system for reporting for veterinary applications*. I am following up to learn more, but I believe that you are supposed to fill out the PDF from this page and e-mail that to CVM1932a@fda.hhs.gov. I think you may need to download the PDF, since it did not render correctly when viewed through my web browser.
To be fair, I wanted to compare the technical replicates compared at the same time. While I think there are some noticeable improvements (such as providing a scale to switch to confident results and I think the percentiles have been removed), I think the point about the breeds might be even more clear:

You can see the top specific breed often changes. I think some things are helped by switching to the confident assignments, even though that wasn't perfect. I think seeing the top exotic result change between the confidence levels might help illustrate what I was saying about the problem with those assignments (such as the very rare Savannah):

I think there is still an issue with the chromosome painting (with the earlier problem explained below the footnotes), but it is the same issue that I encountered when I tried to run the analysis with public SNP chip data (which you can see at the middle of this post, for example).
In general, it seems like the broad ancestry groups are more robust than the specific breeds. However, I thought it might be interesting that Maine Coon was the top Western breed if the confident results are selected (which might have matched the PCA plots that I showed above). That said, you can hover / click the specific breeds to see the chromosomes for each breed. So, the only specific chromosome that is common between the 2 technical replicates was chrB4. However, Bastu is a carrier for the M3 long-hair marker, which is on chrB1. So, these particular reports are not providing evidence that you can identify a segment that is similar to Maine Coon basepaws customers that includes Bastu's 1 copy (out of the needed 2 mutated FGF5 genes to cause long hair) of the M3 mutation in the FGF5 gene. Plus, this is not true for my 15x sequencing report (Russian Blue is above Maine Coon).
Again, to be fair, basepaws makes clear that you should expect reports to be updated. So, as long as you realize this (and don't take any action based upon the lcWGS results), I think this should be OK.
That said, the relatively greater contribution of "Western" ancestry was robust (with the UC-Davis results and my custom re-analysis of the raw higher coverage basepaws WGS data). For example, with an earlier report, if you sum the "Western" (39.2%) and "Persian" (12.4%) contributions from basepaws (51.6% broader "Western"), that is similar to the K=4 ADMIXTURE analysis that I performed on Bastu's higher coverage data (65% Western ancestry). I believe a 10-15% difference in ancestry estimates is relatively similar (and the conclusions are qualitatively the same).
I also had concerns about the use of percentiles, but I don't believe this is in the most recent reports. However, this may be conceptually useful for discussions about things like Polygenic Risk Scores, so I moved that content below the footnotes.
Similarly, I also moved down the content related to the earlier smaller segments below the footnotes (which had a different problem).
basepaws ~15x WGS (regular price $599)
- I think this was supposed to be closer to ~20x, but please note that small fragments decrease the actual genomic coverage
- There are links to download Bastu's raw FASTQ data from the GitHub page
- This is my recommendation for getting raw data (for re-analysis)
- I think you might technically be able to do with with a large enough donation to the 99 Lives project (not related to basepaws), but I think that is probably more about funding research than having a cost-effective way to get sequencing data.
- If you were able to do sequencing on a lower-throughput machine through a DIYbio group, I think that would probably end up being more expensive. However, I think that should be viewed more for training / education, rather than just getting raw data genomic data for your cat.
- There was a fairly long time when I didn't have a report for this sample. However, I more recently noticed that I can now download 3 reports, so I believe the report for my earliest sample was for the this higher coverage sequencing (as of 10/16/2020, you can view the PDF for "possible" results here and "confident" results here).
- While I expect the individual variants / genotypes to be more accurate, I think there is still some room for improvement in the ancestry results (as I currently describe above for the lcWGS + Amplicon-Seq).
- For example, it might be good that there is only "Western" and "Polycat" ancestry at the "confident" setting. However, there are still some noticeable differences between my technical replicates in the last section (which I believe were the same on 10/16/2020, compared to the screenshots for an update for this blog post), including a change in the top breed (which expected was probably less robust / accurate). Nevertheless, I think that the fact that the largest percentage (not on top) was "Broadly Western" was a good sign.
- In terms of the timing, my guess is that new customers probably won't have to wait as long to get the report (which I hope is updated as frequently as the others).
- As a summary, I am showing some views of the 3 official basepaws reports below:
"Possible" Setting for basepaws ancestry report:

"Confident" Setting for basepaws ancestry report:

To be clear, all results that I will now show below are custom analysis of raw data (and should not be expected for other basepaws customers). For example, you can see a custom report that I created for Bastu here. However, please note that the cost used to be higher, so I am listing what I paid (not the current price, which I have tried to update in the blog post).
For the custom re-analysis, one thing that I think is kind of neat is the separation that you can see between Eastern and Western reference samples (even with a relatively small number of probes on the cat SNP chip):

Even if there can be some improvement for the specific species, there is already some noticeable overlap if you try to separate the Persians from the Western cats. However, what I thought might be possibly interesting is that Bastu was arguably slightly closer to the Maine Coon (and the UC-Davis VGL Cat Ancestry showed that she was an M3 carrier, which believe was found in a decent proportion of Maine Coons):

In terms of testing Bastu's mutations from UC-Davis, 2 out of the 3 showed reasonable validation:
Agouti (ASIP, a/a)
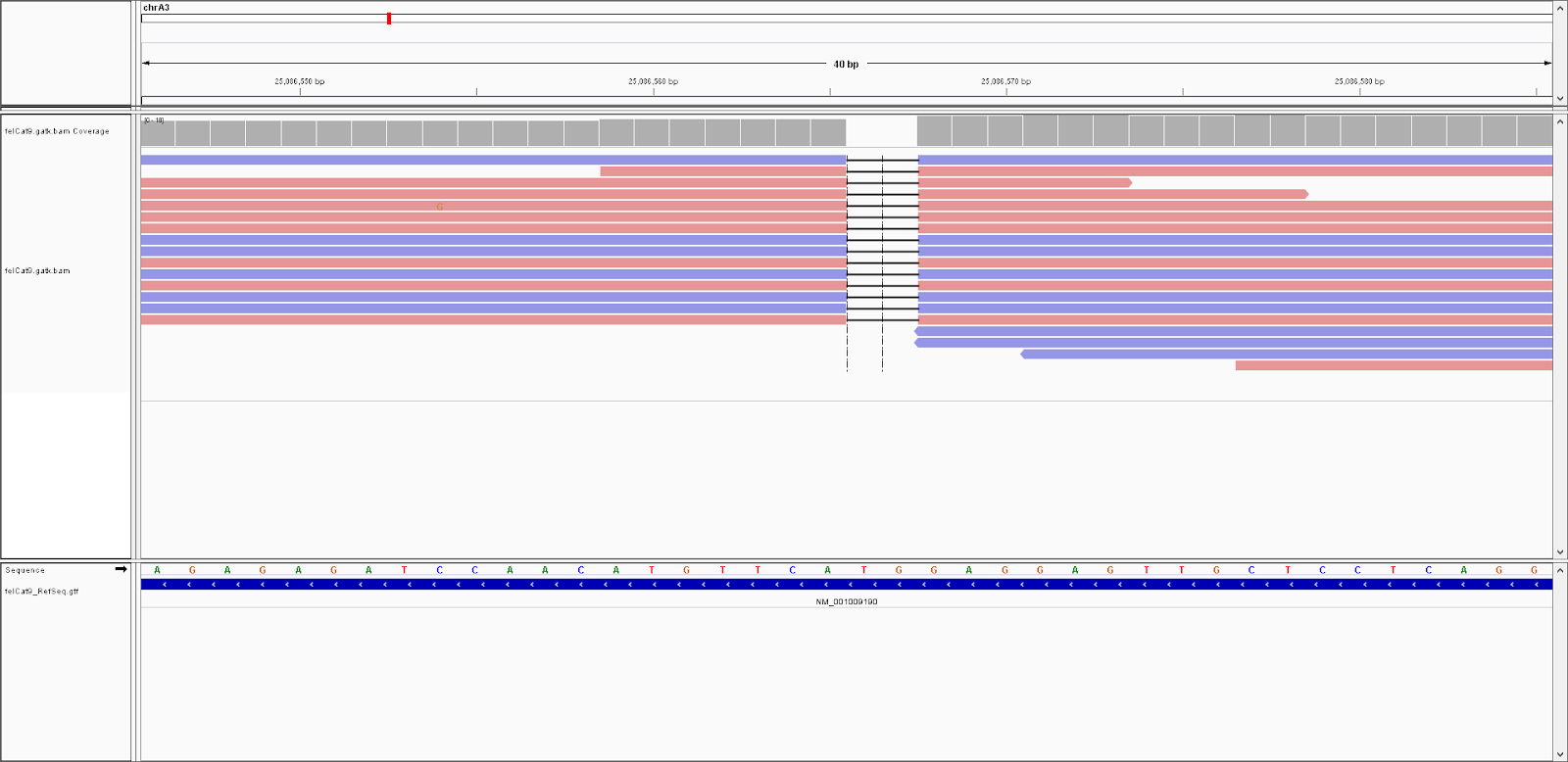
Long Hair (M3/N, FGF5)

I saw one read including the 3rd variant, although I am not sure why it was at so low frequency. At least currently, I don't feel the strong desire to see if I can get something closer to 50% frequency with more starting DNA, but I can leave this as something to ponder for the future (and note that the UC-Davis VGL and Optimal Selection samples were also saliva samples patiently collected from Bastu's cat mouth, although the mechanism was slightly different). Either way, her heterozygous status was validated on the 5th page of the Optimal Selection report (the 2nd page of the "Trait" section), so I believe this is her true genotype (and it's also possible the read ratio may improve with higher coverage).
Dilute (D/d, MLPH)

Optimal Selection / Wisdom Panel Feline (currently $99.99)
- As I mention in my GitHub notes, the company name was a little confusing.
- I also see "Mars" on a lot of the content provided through Optimal Selection, but perhaps this article about Optimal Selection for Dogs can give some extra context?
- More recently, I noticed that I could only download a legacy PDF. So, this might still be important, I moved my earlier screenshot below the footnotes.
- You can see Bastu's report in PDF format here
- At 2 weeks, this report has the fastest turnaround time
- I also believe this provided the largest list of specific mutations (for traits and diseases)
- I think it may be worth mentioning that the current (?) name of the company relates to selecting purebred cats for breeding.
- In other words, I think the basis of this company is to essentially find the most genetically different cats among those that have the specific traits to define the breed (and/or are registered as a purebred cat)
- Even if you can get a little tighter clustering of specific breeds than I showed in the PCA plot above, I think this is somewhat more of an indication that the genome-wide similarities may be better for defining distance (which could be for breeding endangered species, etc.) rather than trying to say "what your pet is made of" for ancestry.
- In other words, even though basepaws indicates they are not a breed test, I worry that those genome-wide distances to breeds described above can cause confusion / misunderstanding for customers.
- I also learned about some additional mutations that I don't believe are currently on the public Davis VGL website for cats.
- While I think they are currently disabled, I could learn some information from the Optimal Seletion help menu (available to those with accounts).
- I think a lot of these come from OMIA (which sounds like OMIM, but I am not aware of an NCBI version of OMIA, unlike OMIM)
- Saliva sample collected with cytobrush (2x, 15 seconds each)
- They currently do not provide raw data (as confirmed via e-mail)
- I also don't believe there is anything about Eastern-Western ancestry (and no raw data for potential re-analysis). This probably isn't crucial for most customers, but this would mean you would may want to consider UC-Davis and/or basepaws if you were interested in that (or wait and see if that gets added in the future - I did suggest creating a PCA plot like I show above for the basepaws higher coverage WGS data, and I think they are considering that).
- So, unless you value raw data (such as with the basepaws $950 WGS FASTQ+BAM+VCF) and/or supporting a non-profit (as with the UC-Davis VGL), this is what I would recommend for ~$100
- That said, I am interested in learning more about cat genetics / genomics. So, I will still make all 4 purchases, even if I had the option to go back in time and make the decision again.
Overall:
Briefly, I would say I have concerns about the ancestry results and how basepaws represents themselves sometimes. However, if you want raw data, I think basepaws provides the best option for that (if you may more for higher coverage sequencing).
Briefly, I would say I have concerns about the ancestry results and how basepaws represents themselves sometimes. However, if you want raw data, I think basepaws provides the best option for that (if you may more for higher coverage sequencing).
I personally like supporting a non-profit like UC-Davis, and I think the information that they provide should be used by everybody.
I am not entirely certain what is happening with Optimal Selection / Wisdom Panel. If you can't purchase that kit, then UC-Davis (and custom re-analysis of raw data) may currently be the only way to check for specific trait mutations in the "Cat Ancestry" test (until basepaws adds those later on).
Finally, since I have been asked by others, I think "Bastu" does mean something (not related to cats), but I was Googling names for cats and that somehow popped up. I like it because it sounds like "Bast 2" (like Bastet, the Egyptian God) and "Babou" (Salvador Dali's pet Ocelot**, referenced on the TV show Archer).

Finally, since I have been asked by others, I think "Bastu" does mean something (not related to cats), but I was Googling names for cats and that somehow popped up. I like it because it sounds like "Bast 2" (like Bastet, the Egyptian God) and "Babou" (Salvador Dali's pet Ocelot**, referenced on the TV show Archer).

Footnotes:
*You can report adverse events for veterinary products to the FDA. However, my understanding is that pre-market approval is not needed before a product is made available.
**To be clear, I am not recommending anybody get an Ocelot as a pet. I just like Ocelots.
Problem with Earlier Smaller Segments (basepaws):

The issue with the above image is that I would have expected more variation in ancestry between the two copies of chromosomes.
They aren't 100% identical, but it seems odd to me to have matching ancestry / variants at the same position in both chromosome copies (scattered on several chromosomes), particularly for presumably rare events like "Exotic" ancestry estimates (if truly unique for a breed). For example, you can see some notes on visual inspection and critical assessment of chromosome painting here (and the concept may be easier to see for my human data).
Earlier Percentile Concerns (basepaws):
I think Bastu may also provide a good example of why you may not want to use the percentile rankings in the basepaws results:


When you view the segments, there is more genome-wide predictions with the Maine Coon (and I think that may also be a better match for her M3 long-haired variant and the custom re-analysis that I performed), even though the percentile was lower than the Norwegian Forest Cat. On the other hand, this may mean others are more likely to have false positives for Maine Coon ancestry segments?


When you view the segments, there is more genome-wide predictions with the Maine Coon (and I think that may also be a better match for her M3 long-haired variant and the custom re-analysis that I performed), even though the percentile was lower than the Norwegian Forest Cat. On the other hand, this may mean others are more likely to have false positives for Maine Coon ancestry segments?
Screenshot for Earlier Interface (Optimal Selection / Wisdom Panel):


There used to be a "public" list of cats and their results (after you have ordered a kit, I think you could use this link). For example, you could see what purebred cat reports look like this way. Likewise, I made Bastu's result public, and you could view that here (completely public, without requiring a sign-in).
I don't currently see this feature. However, I hope that it is added back in.
Change Log:
12/18/2019 - public post
12/21/2019 - minor updates
12/28/2019 - revise content for clarity
1/8/2020 - add a couple more screenshots; update Bastu's report to include Amplicon-Seq disease variants
1/9/2020 - mention longer turn-around time for UC-Davis VGL; remove holiday prices for basepaws
5/8/2020 - add technical replicate results
7/6/2020 - add link to notes on especially large concerns about Savannah Exotic breed index
8/14/2020 - minor changes + remove earlier note about delay in Amplicon-Seq mutation results
8/29/2020 - add draft for submitted FDA MedWatch report
9/3/2020 - add updated technical replicates and summary
9/7/2020 - add updated technical replicates and summary
9/11/2020 - correct confident technical replicate labels and add basepaws Maine Coon maps
9/15/2020 - add Ocelot note / warning
10/6/2020 - add concern about basepaws "biome testing"
10/7/2020 - minor changes / fix typos
10/16/2020 - add regular WGS report (reorganize post now that I have 3 reports); update/check prices for all 4 options
10/17/2020 - give date instead of time for introduction (since the original post was about a year ago); minor changes + revise content to make more clear (and move points that are currently less relevant below the footnotes).
2/20/2021 - update some basepaws notes, clarifying my opinion and adding examples for metagenomic application
2/21/2021 - minor changes + substantial extra information for dental disease
2/22/2021 - minor changes + additional disease prevalence link
2/26/2021 - add link to acknowledge need to say "consumer"
2/27/2021 - add link to VOHC
3/4/2021 - add link to FDA veterinary adverse event reporting
3/5/2021 - add link with FDA veterinary limits
3/14/2021 - add link to newer blog post7/19/2021 - update link / posts
4/16/2023 - add link to alternative, independent YouTube assessment; formatting change when describing earlier format for Optimal Selection results.














